
Craig Rowe
Techlead / Developer
11th January 2010
Paginate and filter with Yahoo Pipes
Rapid decentralisation of our personal content has led many of us to have rather minimal websites with the main content hosted on any number of a variety of web services. The homepage then acts as a hub, virtual business card or placeholder instead.
The half way house
The middle ground then, between the more 'old school' all-in-one personal site and the business card style, are hybrid sites where, although the content may be hosted externally, it is still pulled in to the hub for central display and branding. This is probably the first contact many of us developers/designers have with a new API - trying to access it and pull content in to our personal locations. It can be seen in the large amount of twitter/brightkite/google maps 'badges' across our personal websites.
Indeed, on cargowire itself these three api's are used on top of connections to delicious (currently deactivated) and to a variety of RSS feeds for the headscape barn article listings.
Yahoo YQL and Pipes
The approach to site development described above can mean a large amount of research and development work for each new 'type' of thing you want to bring in to your site. YQL is Yahoo's attempt at helping standardize this for us (something that you will often find Christian Heilmann, one of Yahoo's Developer Evangelists, talking about). However the focus of this article is on another of Yahoo's offerings - Yahoo Pipes.
Pipes has been around for a while now (since back in 2007) and provides a nice GUI interface for accessing and manipulating the kind of data you can use YQL to retrieve. After signing up you will be able to create, manage and publish your pipes. Taking advantage of the documentation and examples provided.
The brief
Flexible pulling in of external feed content - appropriately filtered and limited.
Consider the following example scenarios:
- You are sending requests for external content for inclusion on your webpage. Either:
- Clientside javascript sends an ajax request for content
- The server itself is requesting and merging the response with other content before sending down to the client
- You are creating an iPhone application that intends to display custom or aggregated feed contents.
Without direct control over the feed it can be difficult to retrieve exactly what you need. This can then become an issue for the speed of your application. If I'm on my phone and I want to see the most recent items on a feed I don't want to have to download all 500 archive items before being presented with the top ten.
A simple aggregated Pipe
Below is a screenshot of the yahoo pipes editor. Using drag and drop alone you can select a number of modules from the left toolbar and position them on the canvas area as if sketching a flow chart. Dragging from the connector points allows the flow to be guided through to the pipe output.
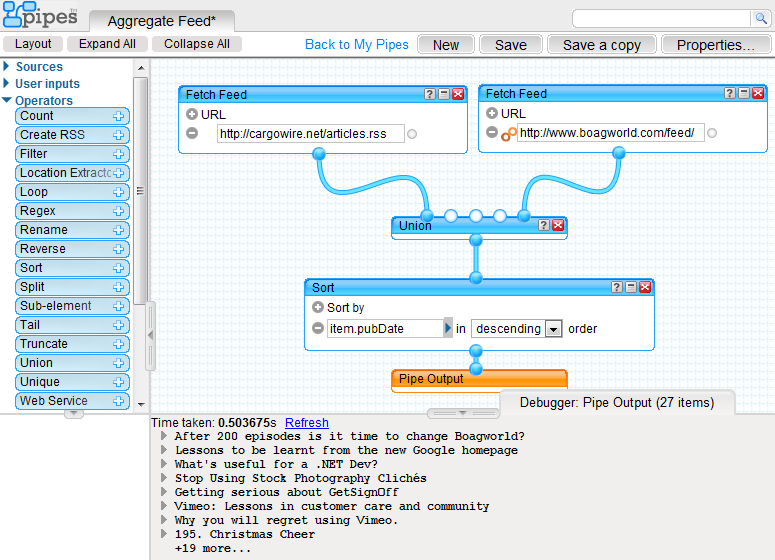
To create an aggregated pipe we use 3 types of module (in addition to the default 'pipe ouput' that comes with a new pipe). 'Fetch Feed' modules are used with an accompanying URL to specify the feed content that you wish to pull in. The 'Union' module under 'Operators' is then used to merge the two feeds together. These all then feed into a simple 'Sort' module which allows you to specify a particular field to sort by (multiple sort fields can be specified by using the 'add (+)' button on this module).
Filtering
So now I have a combined feed of Cargowire and Boagworld. However the Boagworld feed exposed from boagworld.com includes the podcast as well as blog posts...
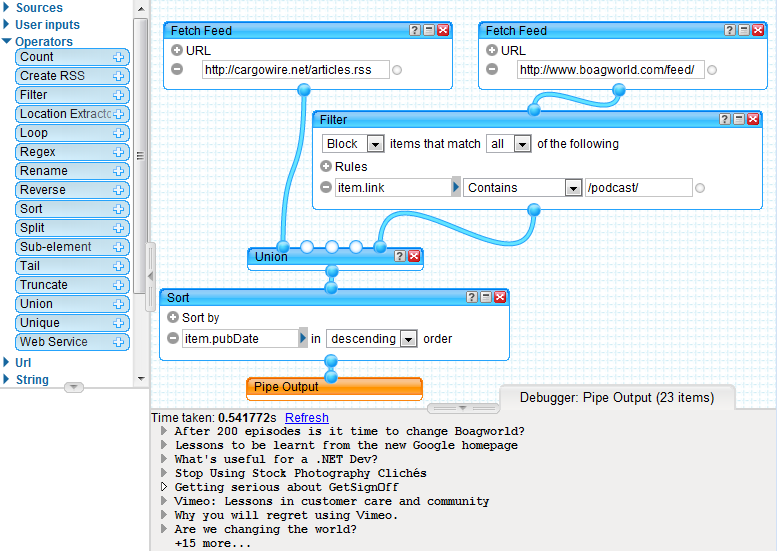
To remove the items that I do not want I can use a 'Filter' module. This type of module can act either as a whitelist or a blacklist by blocking or permitting based on a list of rules. Rules can use the following operators: contains, does not contain, Matches Regex, is greater than, is, is less than, is after, is before. In the example above the items from the boagworld feed are blocked if the link contains the phrase '/podcast/'.
Paginating
With the feeds combined and appropriately filtered my only concern now, in consuming code, is to avoid large datasets when all I want to do is peek at the top 10.
To do this, and to allow my consuming code to control pagination itself, I need to be able to send parameters with my request for the pipe. This can be done using the 'user inputs' modules (which could equally have been used with the 'filter' module above to provide dynamic filtering).
The screenshot below shows the flow of the pipe with this implemented. The following new modules are used:
- Split - will provide two connector points from one
- Count - will count the input items and output a number
- Simple Math - can be used for simple arithmetic
- Number Input - can be used to pull a number from the request querystring
- Tail - takes a number and feed input and returns the items after the specified number position
- Truncate - takes a number and feed input and returns the items up to the specified number position
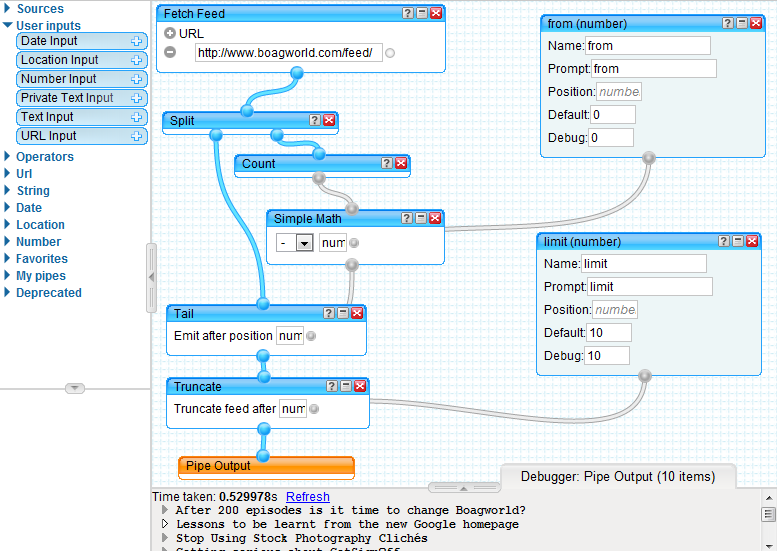
Explanation
-
The feed (or feeds) are fetched and pushed in to a split
- The split is necessary so that the feed contents can be used later as an output but also as the source for calculations
- A count is performed to identify the total number of items in the list
-
A 'Tail' is used to select the count minus a user input 'from' parameter. This
small calculation is performed through the 'Simple Math' module.
- i.e. to select from the 5th item out of 20 I need to 'Tail' the list by 'count' minus 'from' (20-5) or 15
-
A 'Truncate' is then used to select the amount up to the 'limit' parameter
- Combining a tail and truncate allows the specification of a start position and an amount of items to retrieve. e.g. to retrieve the items from 5 to 15 in a list of 20 the user will specify '5' and '10'. The 5 will be calculated against the count and use 'Tail' to retrieve the last 15 items. The truncate will then select the first 10 to result in 5-15.
Using the pipe
By setting a friendly profile and pipe url the paginated feed can then be accessed by any client using:
http://pipes.yahoo.com/cargowire/paginatedboagworld?_render=rss&from=2&limit=5
They can then adjust the viewing parameters as necessary.
By combining all of the above techniques we can use pipes to provide us with an aggregated Headscape Barn feed that is filtered to exclude podcast entries, sorted and then paginated based on user input.
http://pipes.yahoo.com/cargowire/paginatedbarn?_render=rss&from=2&limit=20

Final Thoughts
In this example I have fetched rss feeds, however Yahoo Pipes is also capable of sourcing data from a variety of input sources such as flickr, CSV and plain xml/json. For example I could use a 'Fetch Data' module to pull the same content from my site but using my .xml output instead of .rss. I can then use the 'Rename' module to provide an appropriate output. Equally I could pull content from an API that exposed json through GET requests (such as the twitter public API) and then layer on my own manipulation. Allowing me to implement a large chunk of functionality easily and quickly, delegating all the manipulation code to a third party.
This is exactly the approach taken with the barn feed on this site. The content is pulled from yahoo pipes leaving me only to concern myself with local caching and transforming.
In the case of Cargowire this request is done on the server side with the resulting XML transformed using XSLT into XHTML to send down to the browser. However I could also use the same pipe in JSON format for clientside development or as a simple embed html/script badge (as provided by Yahoo).
Sources / Related Links
All article content is licenced under a Creative Commons Attribution-Noncommercial Licence.









